書誌情報
論文タイトル:A Simple Framework for Contrastive Learning of Visual Representations
論文著者 : Ting Chen et al.
使用コード : https://github.com/Spijkervet/SimCLR
対照学習とは
元の画像とデータ拡張した画像を比較して、拡張後の画像の特徴表現が近くなるように、元の画像とは異なる画像を負として、元の画像と負例画像の特徴表現が離れるように学習を行う。自己教師あり学習の一つ。
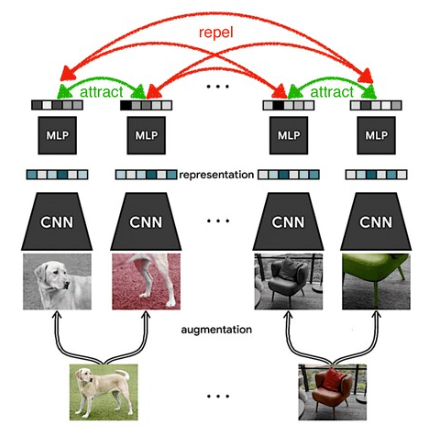
SimCLRの仕組み
SimCLRは画像データの対照学習を行う手法の一種。主に以下の4つの要素から成る。
- data augmentation module
- ある一つの画像データを、3つの方法(ランダムな、切り取り・色の歪ませ・ガウシアンぼかし)を用いて拡張させて、2つの関連したデータを作る(x_iとx_j)
- base encoder f(・) : ResNet
- 拡張データから表現ベクトルを抽出する(h_i, h_j)
- projetion head g(・) : MLP
- contrastive loss空間に表現ベクトルを投影する(z_i, z_j)
- contrastive loss function : NT-Xent
- 拡張データペア(z_i, z_j)を正のデータとして与えることで、ほかの組み合わせ(z_i, z_k{k != j})を負のペアとして損失関数を定義


データセット
STL10
- 10クラス
- ラベル付きデータ:13,000枚
- 学習用データ:5,000枚
- テストデータ:8,000枚
- ラベルなしデータ:100,000枚

目標
STL10データセットのラベルなしデータを用いてSimCLRを用いて自己教師学習した、Logistic回帰モデルが、どれくらいの精度で分類できるかを見てみる
SimCLRを準備する
- Setup the repository
!git clone https://github.com/spijkervet/SimCLR.git
%cd SimCLR
!mkdir -p logs && cd logs && wget https://github.com/Spijkervet/SimCLR/releases/download/1.2/checkpoint_100.tar && cd ../
!sh setup.sh || python3 -m pip install -r requirements.txt || exit 1
!pip install pyyaml --upgrade
#saveというディレクトリが必要なので作っておく
!mkdir savePart1 データの準備
1-1 Install PyTorch/XLA
# whether to use a TPU or not (set in Runtime -> Change Runtime Type)
use_tpu = False
if use_tpu:
VERSION = "20200220" #@param ["20200220","nightly", "xrt==1.15.0"]
!curl https://raw.githubusercontent.com/pytorch/xla/master/contrib/scripts/env-setup.py -o pytorch-xla-env-setup.py
!python pytorch-xla-env-setup.py --version $VERSIONimport os
import torch
import numpy as np
if use_tpu:
# imports the torch_xla package for TPU support
import torch_xla
import torch_xla.core.xla_model as xm
dev = xm.xla_device()
print(dev)
import torchvision
import argparse
from torch.utils.tensorboard import SummaryWriter
apex = False
try:
from apex import amp
apex = True
except ImportError:
print(
"Install the apex package from https://www.github.com/nvidia/apex to use fp16 for training"
)
from model import save_model, load_optimizer
from simclr import SimCLR
from simclr.modules import get_resnet, NT_Xent
from simclr.modules.transformations import TransformsSimCLR
1-2 Load arguments from ‘config/config.yaml’
from pprint import pprint
import argparse
from utils import yaml_config_hook
#コマンドライン引数
parser = argparse.ArgumentParser(description="SimCLR")
#config.yaml内で指定されているconfiguration parameterをコマンドライン引数でargsに格納
config = yaml_config_hook("./config/config.yaml")
for k, v in config.items():
parser.add_argument(f"--{k}", default=v, type=type(v))
args = parser.parse_args([])
args.device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")configuration parameterを確認
### override any configuration parameters here, e.g. to adjust for use on GPUs on the Colab platform:
args.batch_size = 128
args.resnet = "resnet18"
#今回はSTL10(ラベルなしデータ)を指定
args.dataset = "STL10"
#vars(args) : argsを辞書として扱ったときの値を返す
#configuration parameterを確認
pprint(vars(args))いろんなconfiguration parameterが入ってることが分かる
{'batch_size': 128,
'dataparallel': 0,
'dataset': 'STL10',
'dataset_dir': './datasets',
'device': device(type='cuda'),
'epoch_num': 100,
'epochs': 100,
'gpus': 1,
'image_size': 224,
'logistic_batch_size': 256,
'logistic_epochs': 500,
'model_path': 'save',
'nodes': 1,
'nr': 0,
'optimizer': 'Adam',
'pretrain': True,
'projection_dim': 64,
'reload': False,
'resnet': 'resnet18',
'seed': 42,
'start_epoch': 0,
'temperature': 0.5,
'weight_decay': 1e-06,
'workers': 8}1-3 Load dataset into train loader
torch.manual_seed(args.seed)
np.random.seed(args.seed)
#今回はSTL10(ラベルなしデータを含む)を使って結果を見てみる
if args.dataset == "STL10":
train_dataset = torchvision.datasets.STL10(
args.dataset_dir,
split="unlabeled",
download=True,
transform=TransformsSimCLR(size=args.image_size),
)
if args.nodes > 1:
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset, num_replicas=args.world_size, rank=rank, shuffle=True
)
else:
train_sampler = None
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=args.batch_size,
shuffle=(train_sampler is None),
drop_last=True,
num_workers=args.workers,
sampler=train_sampler,
)Part2SimCLRmodelの準備と構築
2-1 SimCLR model, optimizer, learning rate schedulerのload、初期化など
# initialize ResNet
encoder = get_resnet(args.resnet, pretrained=False)
n_features = encoder.fc.in_features # get dimensions of fc layer
# initialize model
model = SimCLR(encoder, args.projection_dim, n_features)
if args.reload:
model_fp = os.path.join(
args.model_path, "checkpoint_{}.tar".format(args.epoch_num)
)
model.load_state_dict(torch.load(model_fp, map_location=args.device.type))
model = model.to(args.device)
# optimizer / loss
optimizer, scheduler = load_optimizer(args, model)
# criterionの初期化 (NT-Xent loss)
criterion = NT_Xent(args.batch_size, args.temperature, world_size=1)
# Setup TensorBoard for logging experiments
#実験結果を可視化してくれる
writer = SummaryWriter()
2-2 対照学習のためのTrain functionの定義
def train(args, train_loader, model, criterion, optimizer, writer):
loss_epoch = 0
for step, ((x_i, x_j), _) in enumerate(train_loader):
optimizer.zero_grad()
x_i = x_i.cuda(non_blocking=True)
x_j = x_j.cuda(non_blocking=True)
# positive pair, with encoding
h_i, h_j, z_i, z_j = model(x_i, x_j)
loss = criterion(z_i, z_j)
loss.backward()
optimizer.step()
if step % 50 == 0:
print(f"Step [{step}/{len(train_loader)}]\t Loss: {loss.item()}")
writer.add_scalar("Loss/train_epoch", loss.item(), args.global_step)
loss_epoch += loss.item()
args.global_step += 1
return loss_epoch
2-3 Start training! (SimCLRモデルの構築)
args.global_step = 0
args.current_epoch = 0
for epoch in range(args.start_epoch, args.epochs):
lr = optimizer.param_groups[0]["lr"]
loss_epoch = train(args, train_loader, model, criterion, optimizer, writer)
if scheduler:
scheduler.step()
# save every 10 epochs
if epoch % 10 == 0:
save_model(args, model, optimizer)
writer.add_scalar("Loss/train", loss_epoch / len(train_loader), epoch)
writer.add_scalar("Misc/learning_rate", lr, epoch)
print(
f"Epoch [{epoch}/{args.epochs}]\t Loss: {loss_epoch / len(train_loader)}\t lr: {round(lr, 5)}"
)
args.current_epoch += 1
# end training
save_model(args, model, optimizer)事前学習したSimCLR modelから得た重みを使ってLogistic回帰の線形評価
(以降は100epoch学習後のSimCLRモデル(checkpoint_100.tar)とlinear_regression.pyを用いた)
Part3 実際に、事前学習したSimCLRモデルから得た重みを使ってロジスティック回帰の線形評価
- セットアップ
import torch
import torchvision
import numpy as np
import argparse
from sklearn.linear_model import LogisticRegression
3-1 関数の定義
- inference関数:SimCLRで得たパラメータを用いて特徴量ベクトルとラベルベクトルを返す
def inference(loader, simclr_model, device):
feature_vector = []
labels_vector = []
for step, (x, y) in enumerate(loader):
x = x.to(device)
# get encoding (ここでSimCLRから得られたパラメータを使う)
with torch.no_grad():
h, _, z, _ = simclr_model(x, x)
h = h.detach()
feature_vector.extend(h.cpu().detach().numpy())
labels_vector.extend(y.numpy())
#if step % 20 == 0:
#print(f"Step [{step}/{len(loader)}]\t Computing features...")
feature_vector = np.array(feature_vector)
labels_vector = np.array(labels_vector)
print("Features shape {}".format(feature_vector.shape))
return feature_vector, labels_vector
- get_features関数:inference関数によって訓練データ、テストデータのnp.arrayを作る関数
def get_features(simclr_model, train_loader, test_loader, device):
train_X, train_y = inference(train_loader, simclr_model, device)
test_X, test_y = inference(test_loader, simclr_model, device)
return train_X, train_y, test_X, test_y- create_data_loaders_from_arrays関数 : dataset を train loaderにloadする関数
def create_data_loaders_from_arrays(X_train, y_train, X_test, y_test, batch_size):
train = torch.utils.data.TensorDataset(
torch.from_numpy(X_train), torch.from_numpy(y_train)
)
train_loader = torch.utils.data.DataLoader(
train, batch_size=batch_size, shuffle=False
)
test = torch.utils.data.TensorDataset(
torch.from_numpy(X_test), torch.from_numpy(y_test)
)
test_loader = torch.utils.data.DataLoader(
test, batch_size=batch_size, shuffle=False
)
return train_loader, test_loader3-2 logistic回帰の訓練関数とテスト関数の定義
def train(args, loader, simclr_model, model, criterion, optimizer):
loss_epoch = 0
accuracy_epoch = 0
for step, (x, y) in enumerate(loader):
optimizer.zero_grad()
x = x.to(args.device)
y = y.to(args.device)
output = model(x)
loss = criterion(output, y)
predicted = output.argmax(1)
acc = (predicted == y).sum().item() / y.size(0)
accuracy_epoch += acc
loss.backward()
optimizer.step()
loss_epoch += loss.item()
# if step % 100 == 0:
# print(
# f"Step [{step}/{len(loader)}]\t Loss: {loss.item()}\t Accuracy: {acc}"
# )
return loss_epoch, accuracy_epoch
def test(args, loader, simclr_model, model, criterion, optimizer):
loss_epoch = 0
accuracy_epoch = 0
#モデルの推論モード
model.eval()
for step, (x, y) in enumerate(loader):
model.zero_grad()
x = x.to(args.device)
y = y.to(args.device)
output = model(x)
loss = criterion(output, y)
predicted = output.argmax(1)
acc = (predicted == y).sum().item() / y.size(0)
accuracy_epoch += acc
loss_epoch += loss.item()
return loss_epoch, accuracy_epoch3-3 データセットの準備
Load arguments from ‘config/config.yaml’ & Load dataset into train loader
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="SimCLR")
config = yaml_config_hook("./config/config.yaml")
for k, v in config.items():
parser.add_argument(f"--{k}", default=v, type=type(v))
args = parser.parse_args()
args.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if args.dataset == "STL10":
train_dataset = torchvision.datasets.STL10(
args.dataset_dir,
split="train",
download=True,
transform=TransformsSimCLR(size=args.image_size).test_transform,
)
test_dataset = torchvision.datasets.STL10(
args.dataset_dir,
split="test",
download=True,
transform=TransformsSimCLR(size=args.image_size).test_transform,
)
else:
raise NotImplementedError
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=args.logistic_batch_size,
shuffle=True,
drop_last=True,
num_workers=args.workers,
)
test_loader = torch.utils.data.DataLoader(
test_dataset,
batch_size=args.logistic_batch_size,
shuffle=False,
drop_last=True,
num_workers=args.workers,
)
3-4 modelの構築(ResNet, SimCLR, Logistic Regression, Adam, Cross Entropy Loss)
#CNNで使うためのResNet encoderを得る
encoder = get_resnet(args.resnet, pretrained=False)
n_features = encoder.fc.in_features # get dimensions of fc layer
# load pre-trained model from checkpoint
simclr_model = SimCLR(encoder, args.projection_dim, n_features)
model_fp = os.path.join(args.model_path, "checkpoint_{}.tar".format(args.epoch_num))
simclr_model.load_state_dict(torch.load(model_fp, map_location=args.device.type))
simclr_model = simclr_model.to(args.device)
simclr_model.eval()
# Logistic Regression
n_classes = 10 # CIFAR-10 / STL-10
model = LogisticRegression(simclr_model.n_features, n_classes)
model = model.to(args.device)
optimizer = torch.optim.Adam(model.parameters(), lr=3e-4)
criterion = torch.nn.CrossEntropyLoss()
3-5 Creating features from pre-trained context model
print("### Creating features from pre-trained context model ###")
(train_X, train_y, test_X, test_y) = get_features(
simclr_model, train_loader, test_loader, args.device
)
arr_train_loader, arr_test_loader = create_data_loaders_from_arrays(
train_X, train_y, test_X, test_y, args.logistic_batch_size
)
3-6 modelの訓練、テスト
for epoch in range(args.logistic_epochs):
loss_epoch, accuracy_epoch = train(
args, arr_train_loader, simclr_model, model, criterion, optimizer
)
print(
f"Epoch [{epoch}/{args.logistic_epochs}]\t Loss: {loss_epoch / len(arr_train_loader)}\t Accuracy: {accuracy_epoch / len(arr_train_loader)}"
)
# final testing
loss_epoch, accuracy_epoch = test(
args, arr_test_loader, simclr_model, model, criterion, optimizer
)
print(
f"[FINAL]\t Loss: {loss_epoch / len(arr_test_loader)}\t Accuracy: {accuracy_epoch / len(arr_test_loader)}"
)結果
STL10データセットのラベルなしデータを用いてSimCLRモデルを適用した場合の分類結果と、ラベル付きデータを用いて、画像認証ライブラリtimm (https://github.com/rwightman/pytorch-image-models)から、CNNモデルResNet18を適用した場合の分類結果の比較は、以下のようになった。
| Loss | Accuracy | ||||
| SimCLR | 0.520 | 0.824 | |||
| ResNet18 | 0.814 | 0.800 |
したがって、SimCLRモデルは、ResNetモデルよりも損失の値が小さく精度が高いため、ラベルなしデータを有効活用できるということが分かった。


コメント