書誌情報
論文タイトル:A Survey on Federated Learning Systems: Vision, Hype and Reality for Data Privacy and Protection
arxivに2019年にver1、2021年にver5がでる
このサーベイでは、連合学習システム(FLS)の定義、FLSの要素、FLSの分類、FLSの関連研究まとめ、FLSのこれからの方向性について説明している
このブログでは特に4章の、6つの要素(データの配置のされ方、機械学習モデル、プライバシー機構、通信構造、連合のスケール、連合のモチベーション)をもとにした連合学習の分類について詳しくみていく
その他参考論文:
- Federated Machine Learning: Concept and Applications
- A Survey on Federated Learning: The Journey from Centralized to Distributed On-Site Learning and Beyond
Federated Learning
Federated Learning(FL)は、プライバシーの観点からデータを外に持ち出せないときに、複数のデータの所有者が協力して共有の機械学習モデルを訓練する方法である
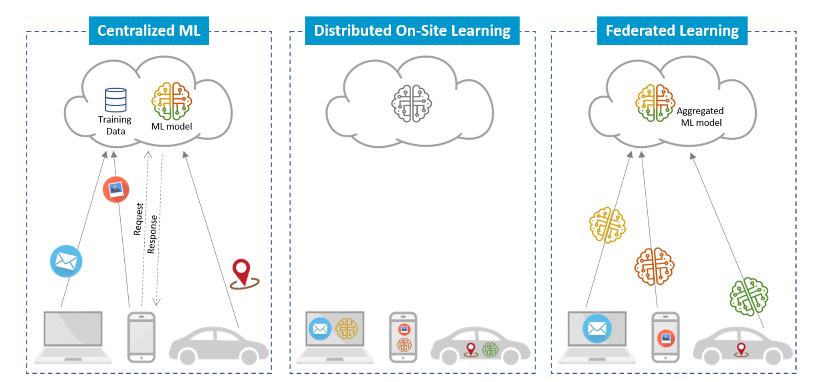
昔からFLと似たような概念はあるものの、近年の大衆のプライバシー意識の高まりにより、データを外に持ち出すことが難しくなっており、急速にFLに関する論文の数が増加している
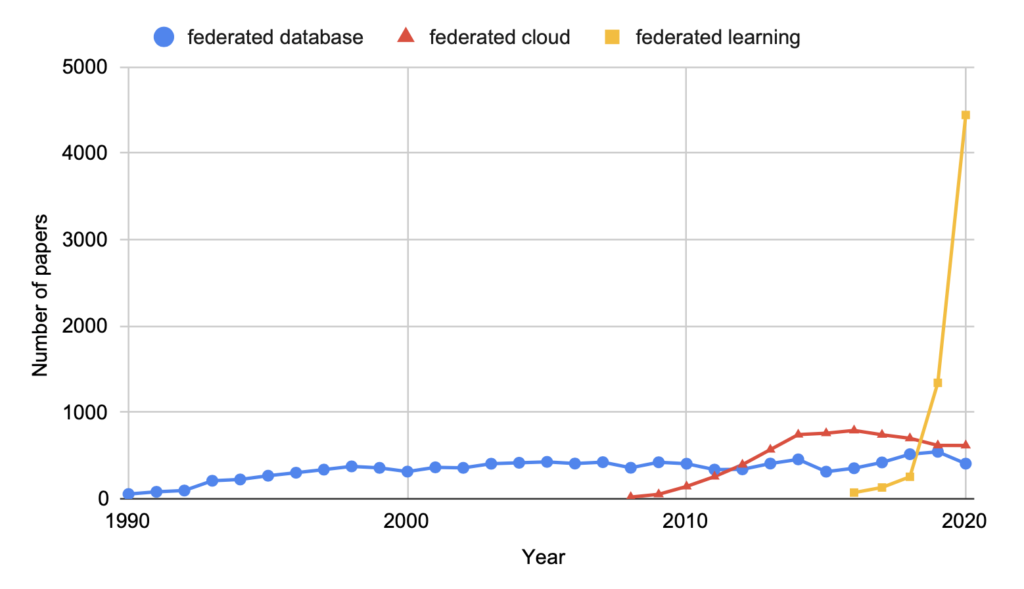
有象無象のFLの論文を俯瞰的にみるために、このサーベイを通してFLを分類するための観点を学ぶ
このサーベイでの連合学習システムの分類
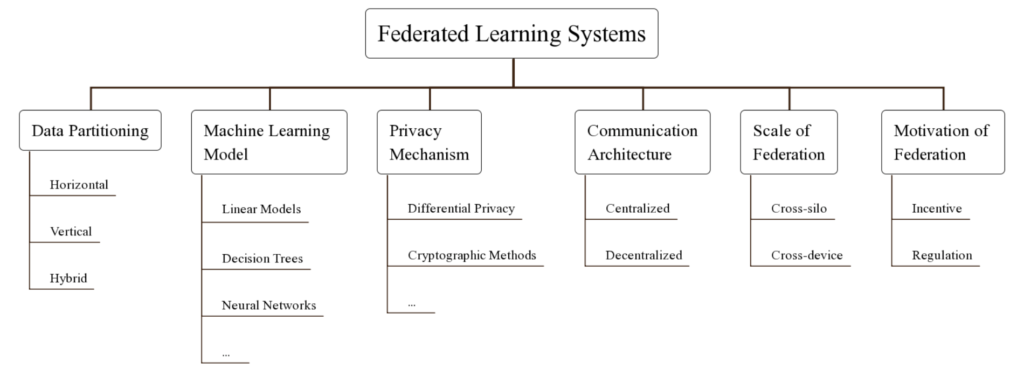
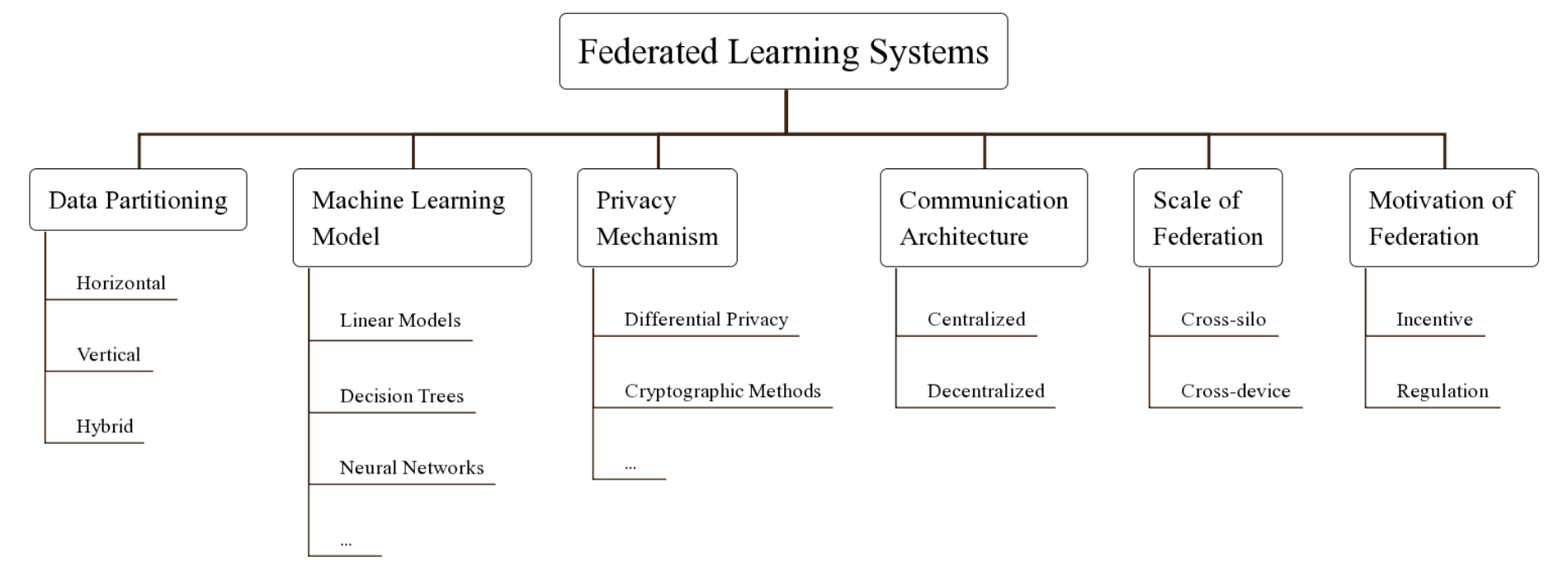
連合学習システム(FLS)は以下の6つの要素で分類することができる
Data Partitioning
Data Partitioningは、データがどのように各データの所有者に配置されるかである
Data Partitioningには水平型・垂直型・混合型の三種類が存在する
水平型の配置は、扱うデータセットの特徴は共有しているが、サンプルが異なる場合である
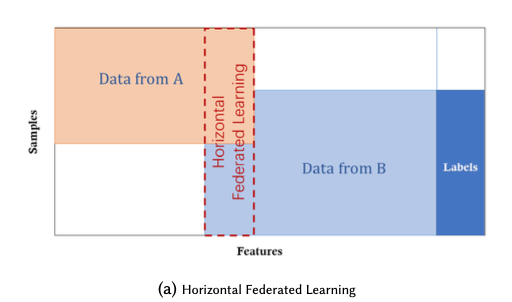
例えば、2つの地域の銀行が地域ごとに異なる顧客を抱えているとする。それぞれの銀行のインターセクションは小さいが、扱うデータは同じである
ほとんどのFLでは水平型配置を扱っている
垂直型の配置は、水平型とは逆で、扱うデータセットのサンプルは同じだが、特徴空間において異なる
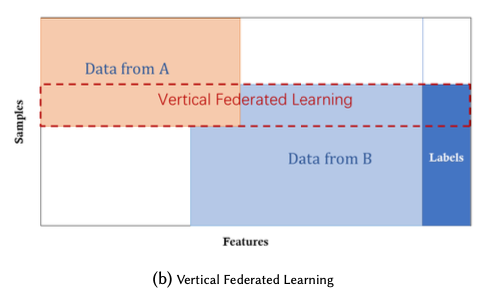
例えば、同じ街の2つの異なる会社があり、一つは銀行、もう一つはeコマースの会社だとする。彼らのユーザのインターセクションは大きいが、銀行の持つデータとeコマースのデータは全く異なっている
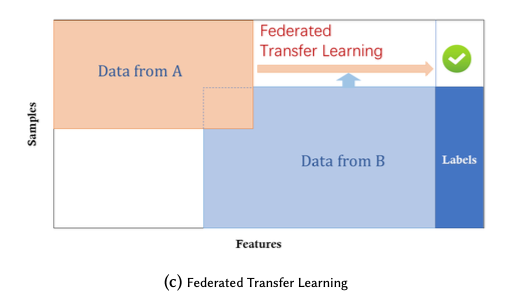
混合型の配置は、データセットのサンプルも特徴空間も異なる配置である
例えば、複数の病院ががん診断のためのFLSを構築したいとする。しかし、それぞれの病院の患者は異なる上、彼らの病気ががんであるとは限らない
連合転移学習は上記を解決する一つの方法である
Machine Learning Model
最も人気なのはニューラルネットワークだが、gradient boosting decision trees (GBDTs), random forests, 線形モデルやSVMも使われているとのこと
Privacy Mechanism
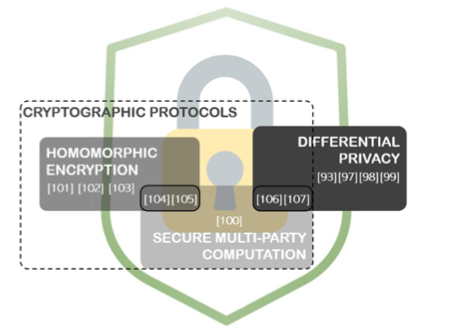
Privacy Mechanismにおいて主流な方法は、暗号化と差分プライバシーである
暗号化として、準同型暗号や秘密計算が有名であり、プライバシー保護の機械学習で広く使われている
基本的に、メッセージを送る前には暗号化をおこない、メッセージを得るときには復号化を行う
そのようにして、連合学習システムのユーザープライバシーは守られる
差分プライバシーは個人データのプライバシーを保護しつつもそのデータを扱うためのシステムである
具体的には、データやモデルパラメタにランダムノイズを乗せることで、個々のレコードのプライバシーを保障する
Communication Architecture
FLSの通信には主に、集中型と分散型がある
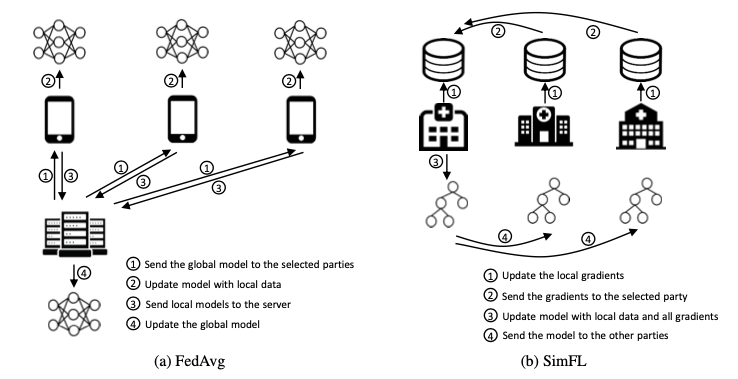
集中型(左図)ではデータの流れは非対称で、マネージャーがローカルモデルの情報を集計し、グローバルなパラメータをアップデートする
集中型はFLで広く使われているが、サーバーの潜在的なリスクを考えたときに分散型のほうが好まれることがある
分散型(右図)では通信が直接データの所有者同士で行われ、すべてのデータの所有者がグローバルなパラメータを更新することができる
分散型ではすべてのデータの所有者がフェアに扱われるような設計にするのは難しい問題がある
また、中心のサーバーが存在せず、訓練が各データの所有者上で行われるため、データの所有者の数に比例して通信コストが大きくなる問題もある
Scale of Federation
連合のスケールはcross-deviceとcross-siloの2つの典型的なタイプがある
cross-device(左図)はデータの所有者自体の数が多いが、データや計算資源は少ない設定である
モバイル機器をイメージするとわかりやすい
デバイスのエネルギー消費問題やデバイスとサーバの不安定な通信問題を考慮する必要がある
cross-silo(右図)はデータの所有者自体の数は多くないが、データや計算資源は比較的十分にある設定である
データの所有者が組織やデータセンターをイメージするとわかりやすい
Motivation of Federation
各データの所有者がFLSに関わるためにはモチベーションが必要であり、そのモチベーションとはレギュレーションやインセンティブのことである
FLSの成功のためにはインセンティブ設計は重要であり、ブロックチェーンのインセンティブ設計は成功した一例である
既存研究の分類
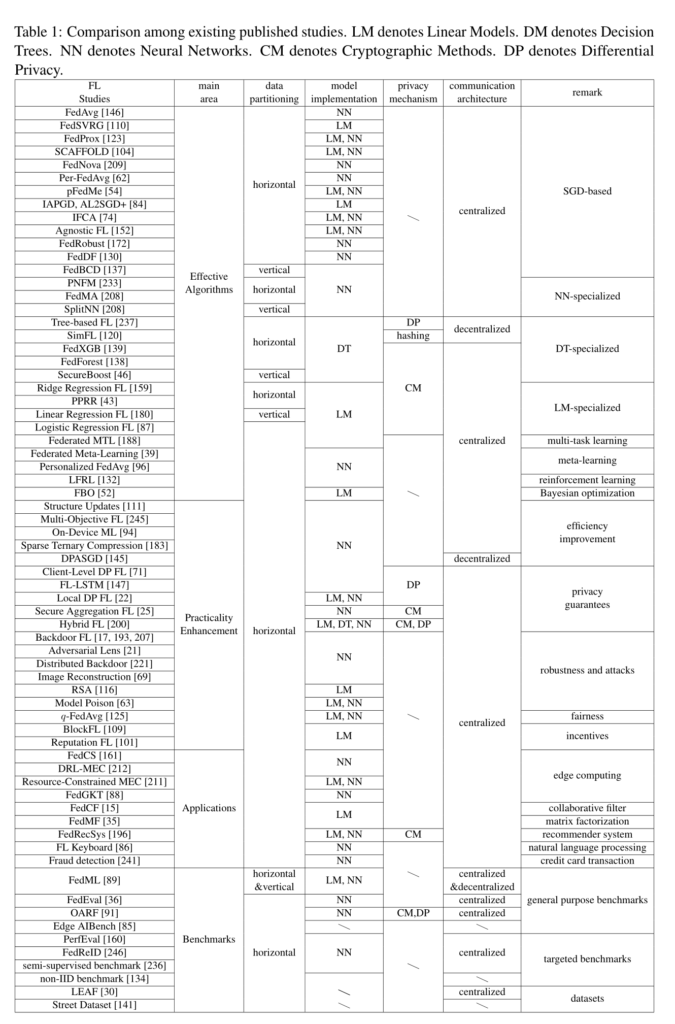
上記分類をもとに、既存研究は以下の表のようにまとめられている
上記分類を頭にいれておくことは、これからのFLの論文の位置づけを知るのに便利かも!
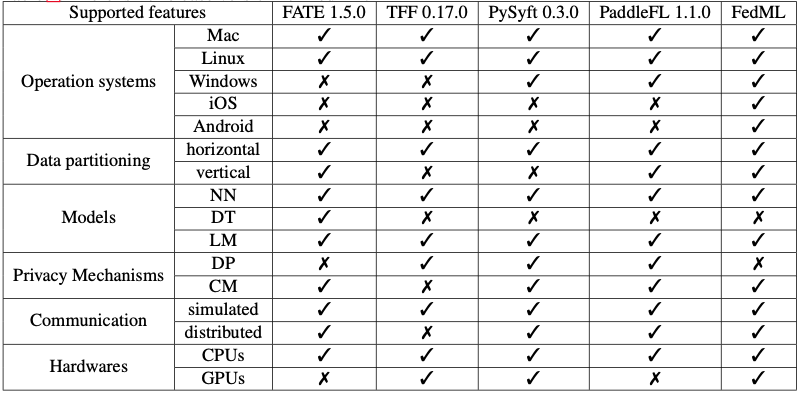
Open Source Systems
open sourceのわかりやすい比較表もあり、自分は前回の記事でPySyftを紹介した

コメント