
書誌情報
論文タイトル:DatasetGAN: Efficient Labeled Data Factory with Minimal Human Effort
論文リンク:https://nv-tlabs.github.io/datasetGAN/
概要:StyleGANの特徴マップから抽出した画素ごとの特徴を入力、少数の合成画像の画素ごとのアノテーションを教師とし、MLPを学習することで、DatasetGANは「無限」のデータセットとそのアノテーションを生成する
提案手法
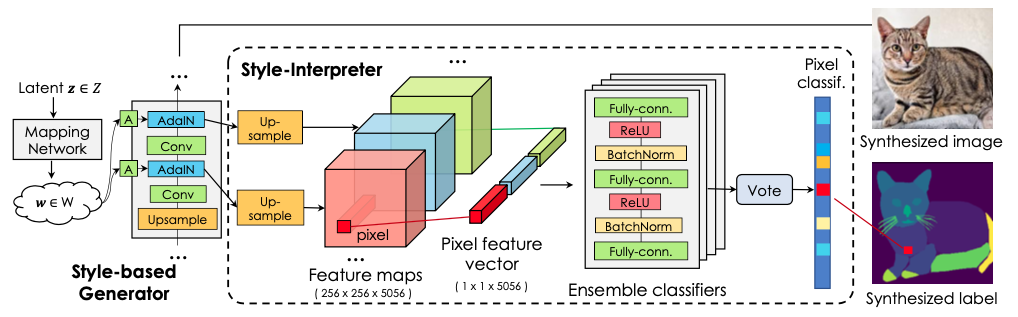
この図が提案手法のすべて
論文の著者
リアルな画像を出力できるGANのような生成モデルは、高次元の潜在空間上で意味的な知識を獲得しているのではないか…?
学習の流れ
あらかじめStyleGANは学習させておく(それかpretrainedモデルを使う)
StyleGANのAdaIN層の特徴マップを全て取り出し、最も大きいサイズの特徴マップに形をあわせるためにupsampleしたあと、結合させる
結合させた特徴マップから、各画素ごとに特徴ベクトルを抽出し、これを入力とする
解釈器と呼ばれるアンサンブルのMLP(実験では10個)を用意し、画素ごとに合成画像のラベルを多数決で予測する
StyleGANの合成画像をもとに、人間による少数の画素ごとのアノテーションを教師として用意し、解釈器を学習させる
「無限」に合成画像とそのアノテーションが生成できるモデルの完成…!
細かいテクニック
StyleGANはときにゴミデータを生成してしまうので、推論時に解釈器の不確かさが高いときはデータとして利用しない
解釈器を学習する際、StyleGANに勾配は流さないようにする
実験結果
人間がアノテーションしたとき(groundtruth)と遜色のない結果に

生成されたデータを使って、試しに好きなモデルで訓練してみよう!

コメント