前回の記事( https://panhouse.blog/paper/implementation/confidenced_based_active_learning/ )の最後でself-trainingに少し触れたが、それの実装を行う。
self-trainingとは、モデルの予測の信頼度が高いものを正解としてしまい、訓練データに加える手法である。
実験設定
データセット:CIFAR10
– 訓練:50000枚
– テスト:10000枚
– 10クラス
モデル:efficientnet-b0
実験結果
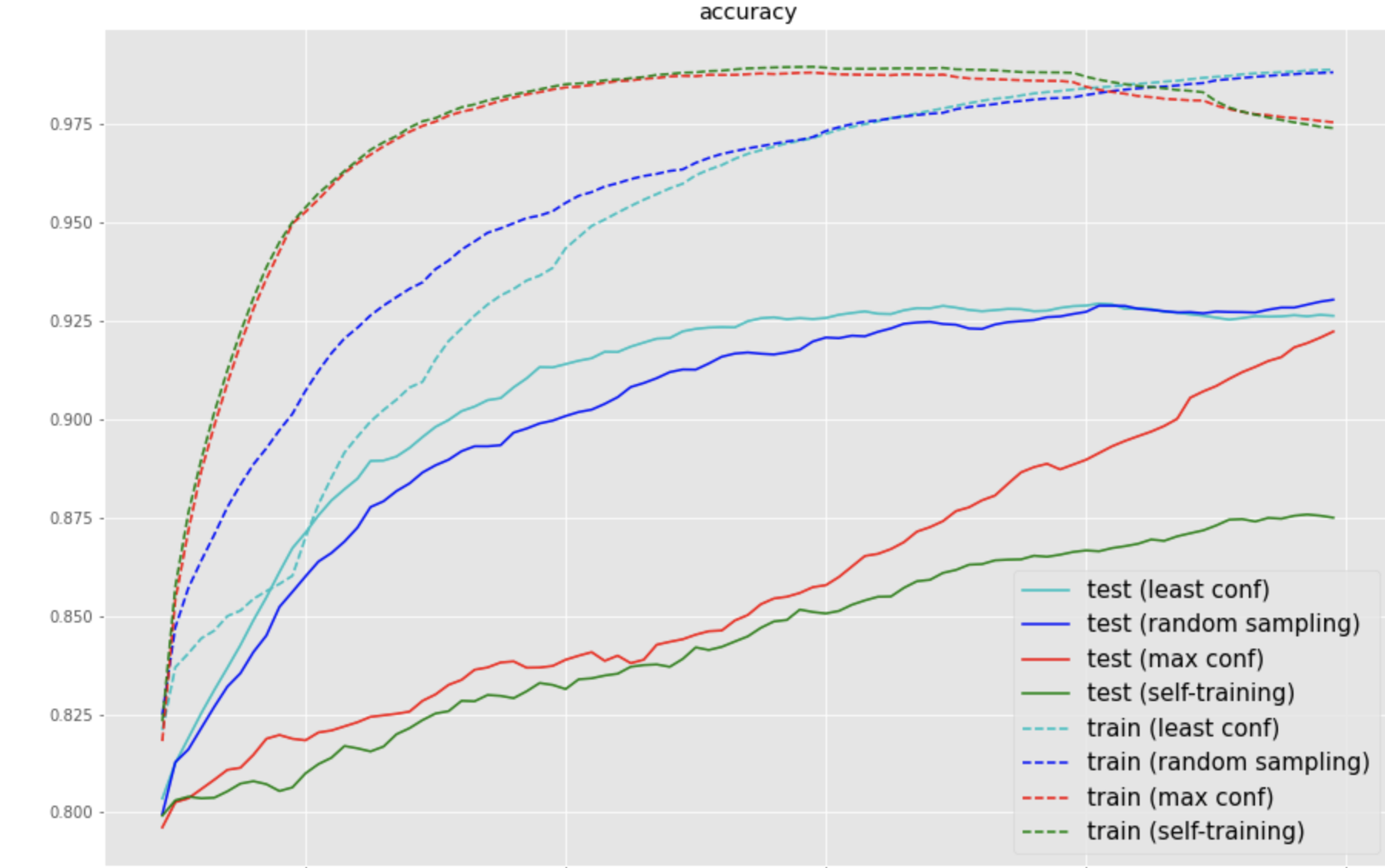
モデルが予測した信頼度が高い画像を5000枚ずつ、予測をそのままラベルとして訓練データに加え、10epochずつ訓練しながらaccの変化をみる
画像の初期枚数は5000枚とする
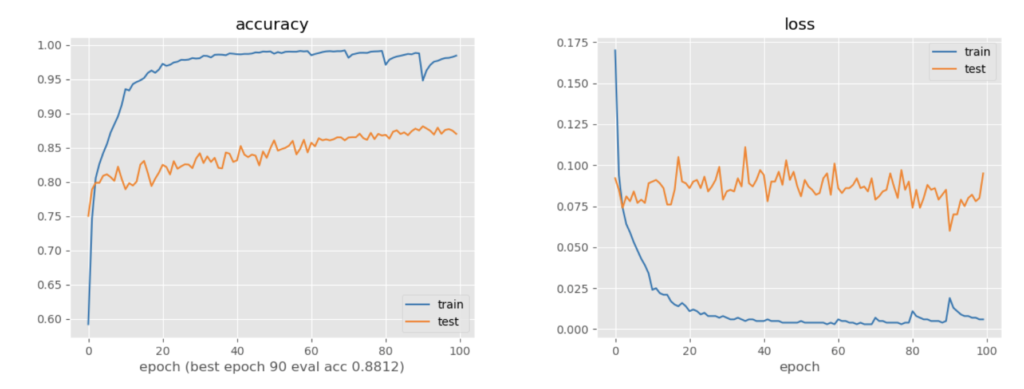
最高正解率は0.88となり、5000データのみで学習したときの0.83程度からラベルなしで0.05程度正解率が上昇していることがわかる
実験考察
移動平均した結果を前回の結果に加えてグラフにした
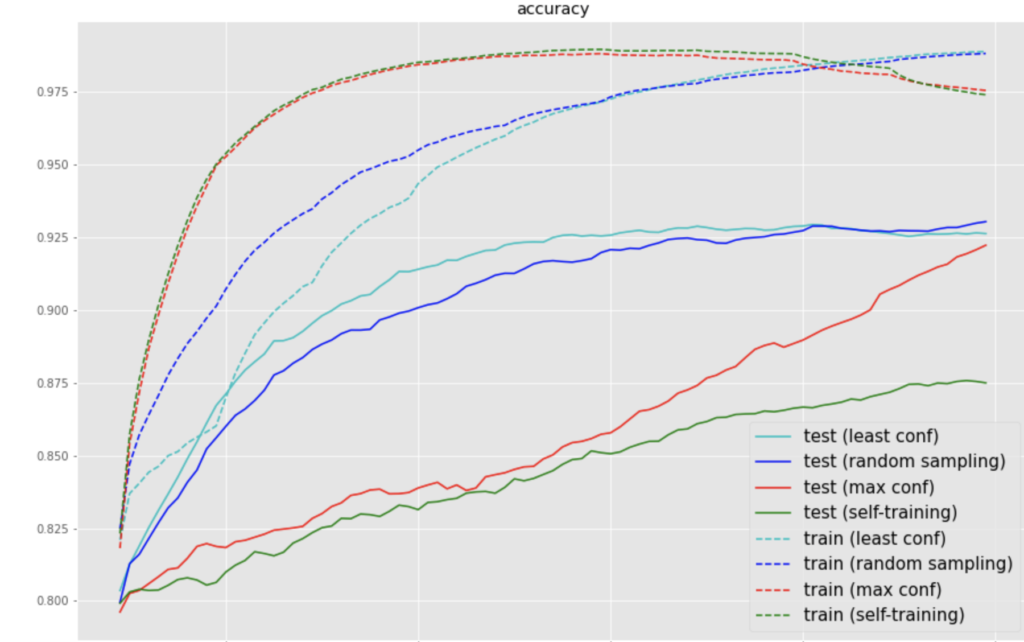
前回の実験より、least confはrandom samplingやmax confよりも収束が早いが、最終的には同じ情報を使っているので、ほぼ同じ精度に収束していることがわかる
信頼度が高い順に加えたmax confはデータに与えるラベルがすべて正しいという条件のactive learningなので、self-trainingのオラクルだとみなせる
self-trainingは、max confよりも正解率の推移が低く、もとの正解率より少しずつ高くなっており、挙動として正しそうであることがわかる
実装抜粋
前回のコードに数行追加するだけ
信頼度高い順に並べ替えを行う
if epoch_ == self.epochs - 1:
print("select data")
model.eval()
conf, pseudo_labels = [], []
for xs, _ in tqdm(restloader):
xs = xs.to(device)
with torch.no_grad():
outputs = model(xs)
softmax_max, preds = torch.max(torch.softmax(outputs.data, 1), 1)
conf.extend(softmax_max.detach().cpu().numpy())
pseudo_labels.extend(preds.detach().cpu().numpy())
conf = np.array(conf)
pseudo_labels = np.array(pseudo_labels)
argsort = conf.argsort()[::-1]
new_indices = rest_indices[argsort][:N]予測結果を正解データに置き換えを行う
for j in range(self.M):
phase = "train"
len_train = len(train_dataset)
if j==0:
indices = np.random.permutation(np.arange(len_train))
N = int(len_train/self.M)
init_indices = indices[:N]
rest_indices = indices[N:]
subset = Subset(train_dataset, init_indices)
rest_subset = Subset(train_dataset, rest_indices)
else:
targets = np.array(train_dataset.targets)
targets[rest_indices] = pseudo_labels
train_dataset.targets = targets
init_indices = np.append(init_indices, new_indices)
rest_indices = np.delete(rest_indices, argsort[:N])
subset = Subset(train_dataset, init_indices)
rest_subset = Subset(train_dataset, rest_indices)コード全体:https://github.com/HironoOkamoto/active-learning/blob/main/pseudo_labeling.py
おまけ
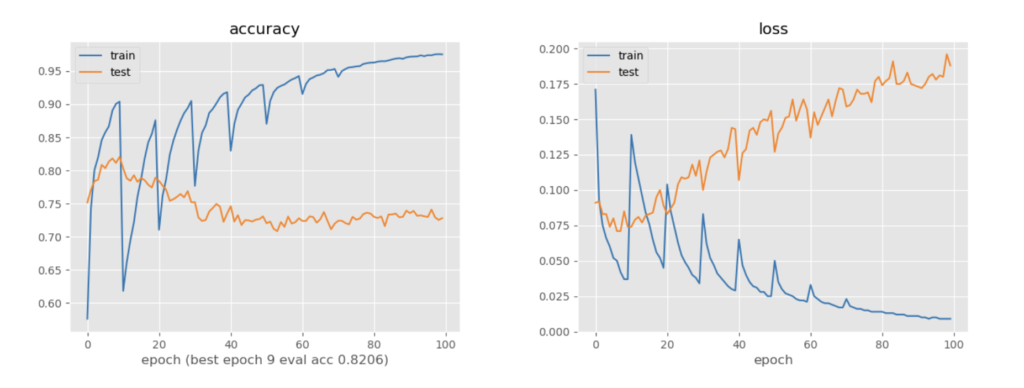
信頼度が低い順に予測を訓練ラベルとして追加していくと、当然性能はむしろ落ちていく


コメント