
この記事を元に解説する
Federated Learningの参考:
- A Survey on Federated Learning Systems: Vision, Hype and Reality for Data Privacy and Protection
- Communication-Efficient Learning of Deep Networks from Decentralized Data
Federated Learning
Federated Learning(FL)は、プライバシーの観点からデータを外に持ち出せないときに、複数のデータの所有者が協力して共有の機械学習モデルを訓練する方法である
データの所有者は例えば病院やモバイル機器を想定するとわかりやすい
PySyftはFederated Learningのための一つのライブラリであり、PytorchやTensorflowと一緒に利用可能である
PySyftはFLで代表的なアルゴリズムであるFedAvgが実装されている
FedAvg
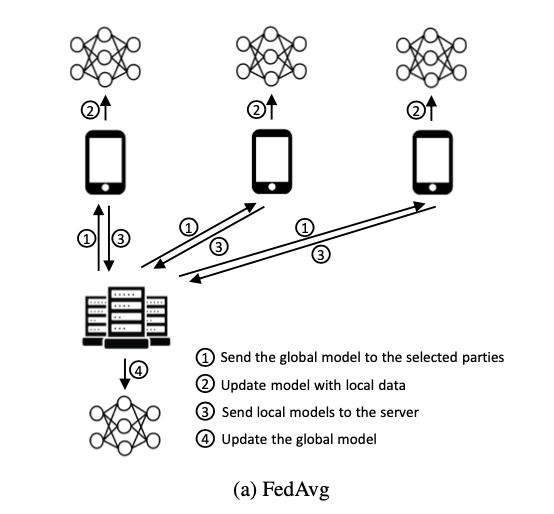
上図をもとにFedAvgの説明を行う。アルゴリズムは1~4を繰り返したものになる
- サーバから各デバイスにモデルを送る
- 各デバイスでミニバッチ数$B$のデータを利用し、$E$回重みの更新を行う
- サーバにパラメタの重みを送信する
- 各デバイスから受け取った重みをデバイスのデータ数で荷重平均したものをグローバルな重みとする
※E=1, B=「全てのデータ」としたとき、FedSGDというアルゴリズムと同等になる。E,Bを調整することで、性能はFedAvg > FedSGDとなる
PySyftを使ってFLの実装
まずはtorchをインポート
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transformsデータの所有者をbobとaliceとする
import syft as sy # <-- NEW: import the Pysyft library
hook = sy.TorchHook(torch) # <-- NEW: hook PyTorch ie add extra functionalities to support Federated Learning
bob = sy.VirtualWorker(hook, id="bob") # <-- NEW: define remote worker bob
alice = sy.VirtualWorker(hook, id="alice") # <-- NEW: and aliceここでv0.3.0+を使っていると、syftにtorchhookがないと言われてしまう
pip install syft==0.2.9 を使おう
ハイパーパラメータの設定を行う
class Arguments():
def __init__(self):
self.batch_size = 64
self.test_batch_size = 1000
self.epochs = 10
self.lr = 0.01
self.momentum = 0.5
self.no_cuda = False
self.seed = 1
self.log_interval = 30
self.save_model = False
args = Arguments()
use_cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed)
device = torch.device("cuda" if use_cuda else "cpu")
kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}「.federate」を利用して、bobとaliceでMNISTのデータを分割する。テストデータは通常のデータローダを使う
federated_train_loader = sy.FederatedDataLoader( # <-- this is now a FederatedDataLoader
datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
.federate((bob, alice)), # <-- NEW: we distribute the dataset across all the workers, it's now a FederatedDataset
batch_size=args.batch_size, shuffle=True, **kwargs)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.test_batch_size, shuffle=True, **kwargs)単純な構造のCNNを用意する
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5, 1)
self.conv2 = nn.Conv2d(20, 50, 5, 1)
self.fc1 = nn.Linear(4*4*50, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = x.view(-1, 4*4*50)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)モデルを各データの場所に送り(model.send)、モデルをアップデートしたあとに、モデルを回収する(model.get)という点で通常の訓練とは異なる
def train(args, model, device, federated_train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(federated_train_loader): # <-- now it is a distributed dataset
model.send(data.location) # <-- NEW: send the model to the right location
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
model.get() # <-- NEW: get the model back
if batch_idx % args.log_interval == 0:
loss = loss.get() # <-- NEW: get the loss back
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * args.batch_size, len(federated_train_loader) * args.batch_size,
100. * batch_idx / len(federated_train_loader), loss.item()))
テストは通常のやり方
def test(args, model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))訓練を行う。通常の2倍弱の計算時間がかかる
model = Net().to(device)
optimizer = optim.SGD(model.parameters(), lr=args.lr) # TODO momentum is not supported at the moment
for epoch in range(1, args.epochs + 1):
train(args, model, device, federated_train_loader, optimizer, epoch)
test(args, model, device, test_loader)
if (args.save_model):
torch.save(model.state_dict(), "mnist_cnn.pt")MNISTの訓練程度であれば、NEWとコメントで書かれている数行のコードの追加のみでFLができることがわかった
追記
自分が勉強したブログは古いものでしたので、上記ツイートを参考にしていただけたら幸いです
オンラインコース:https://courses.openmined.org/
使用例:https://github.com/OpenMined/PySyft/tree/dev/packages/syft/examples/federated-learning/model-centric
コメント