仕事でactive learningを実装することになったのだが、少なくともCIFAR10使って精度でないものを使ってもしょうがないということで、ベースラインとして簡単な実装を試みた。
信頼度ベースのactive learningとはモデルの信頼度が低いものから逐次的に訓練データに追加しながらモデルを学習し、テストデータの正解率の収束を早くするための方法である。
このような手法を利用することで、効率的にアノテーションを追加することができ、アノテーション枚数を減らすことができると考えられる。
実験設定
データセット:CIFAR10
– 訓練:50000枚
– テスト:10000枚
– 10クラス
モデル:efficientnet-b0
行った実験
– 最初から50000枚与えて、20epoch訓練する
– Randomに訓練データを5000ずつ増やし、10epochずつ訓練しながらaccの変化をみる
– モデルが予測した信頼度が低い画像を5000ずつ増やし、10epochずつ訓練しながらaccの変化をみる
実験
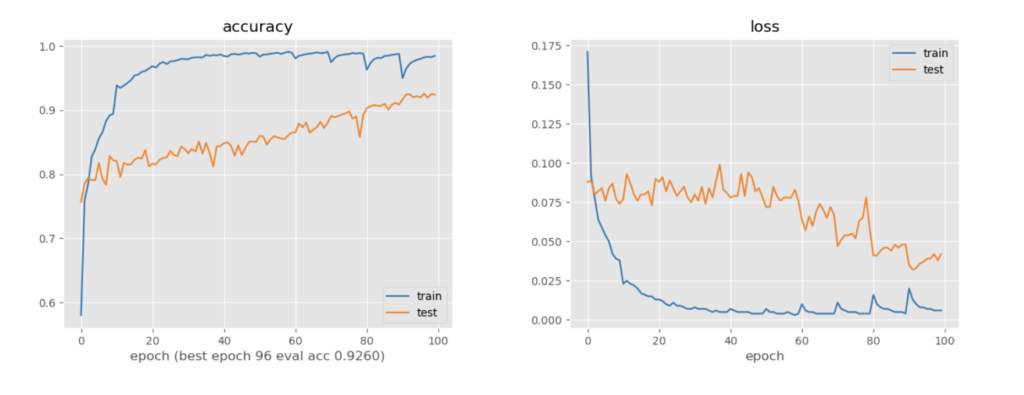
最初から50000枚与えて、20epoch訓練する
正解率0.935でることを確認した

Randomに訓練データを5000ずつ増やし、10epochずつ訓練しながらaccの変化をみる
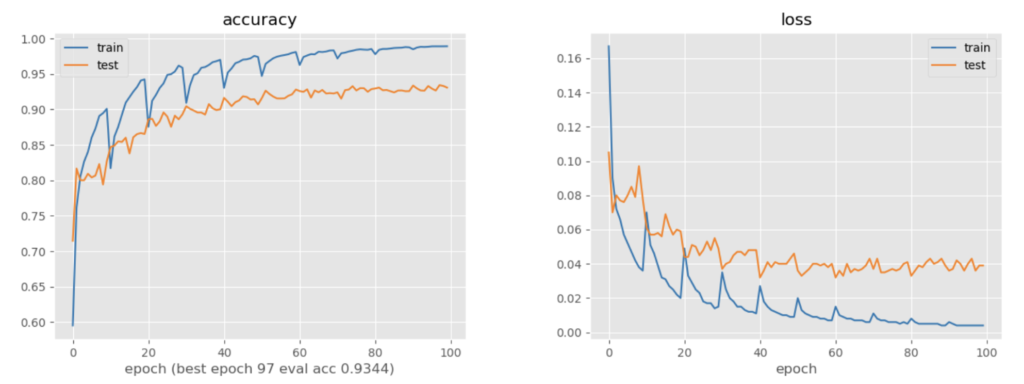
新しく訓練データが増えるタイミングで訓練データの正解率が下がっていることがわかる
モデルが予測した信頼度が低い画像を5000ずつ増やし、10epochずつ訓練しながらaccの変化をみる
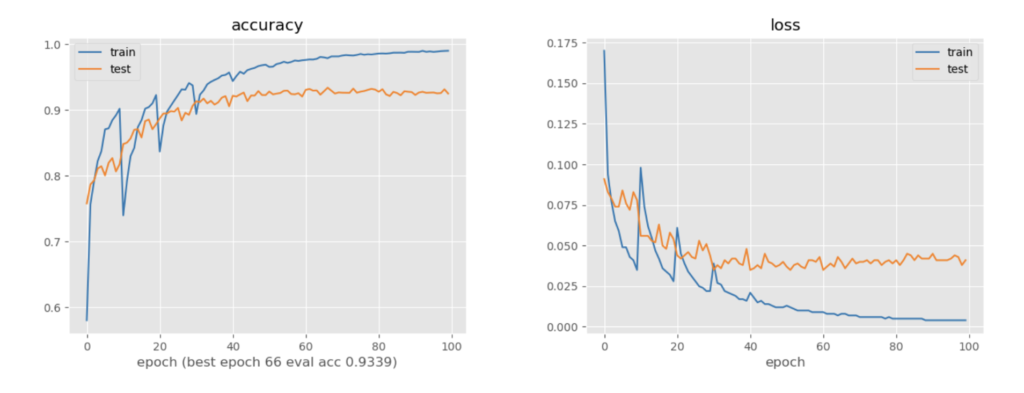
ランダムで訓練したときよりも、新しく訓練データが増えるタイミングの訓練データの正解率の下がり幅が大きいことがわかる→信頼度が低いものから順に訓練データに追加されていることが確認できる
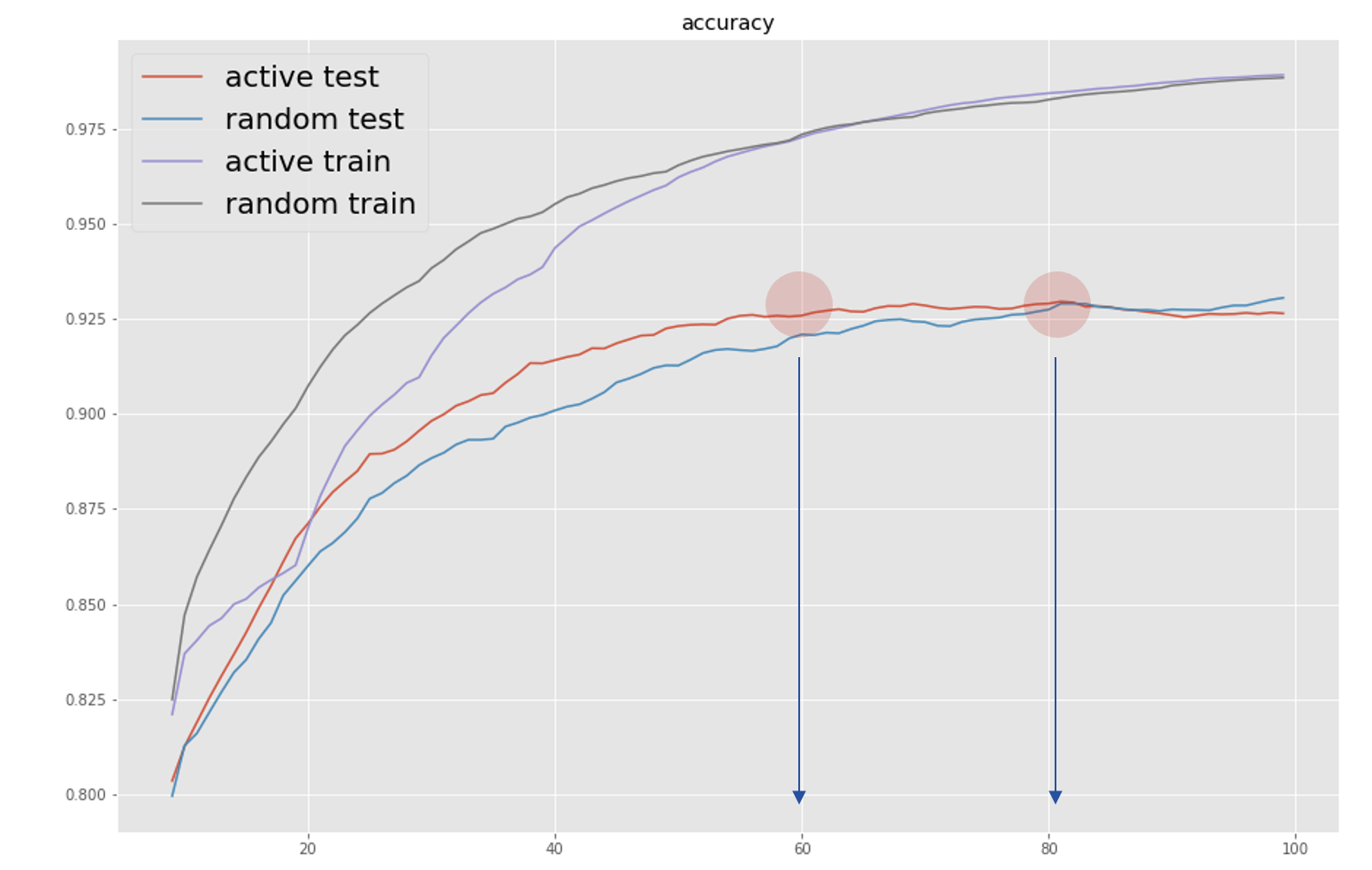
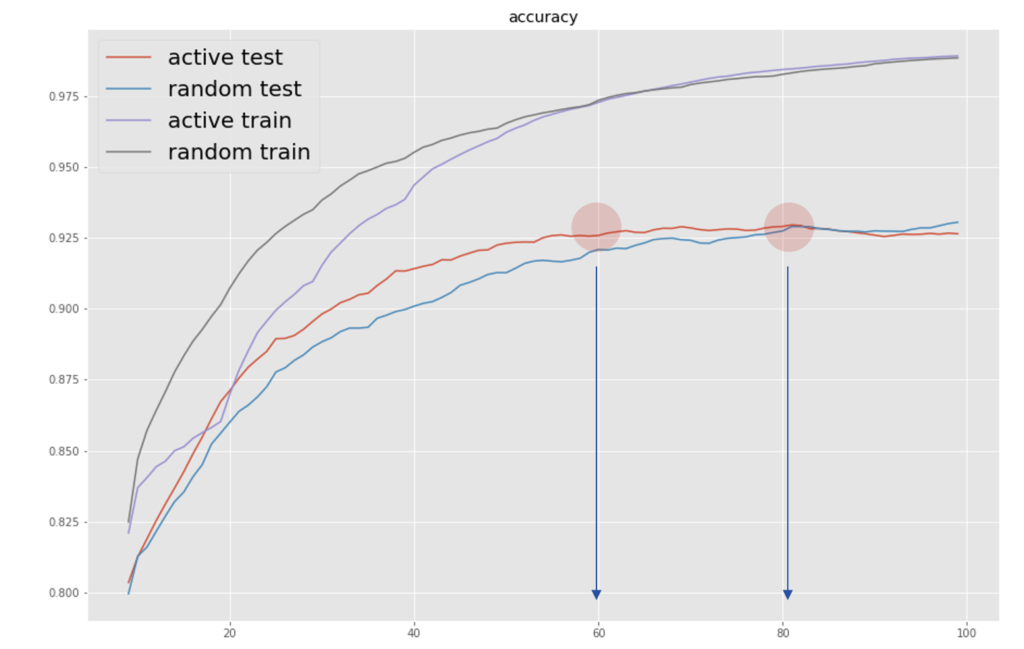
実験結果まとめ
正解率の移動平均(10)をとり、これまでの結果を比較した
randomに訓練データ追加した場合に比べて、モデルの信頼度を利用した場合の収束は20%程度早いことがわかった
実装抜粋
torchのSubset関数を利用した
randomに追加していく場合(実装全体:https://github.com/HironoOkamoto/active-learning/blob/main/random_additional_learning.py)
for j in range(self.M):
phase = "train"
len_train = len(train_dataset)
indices = np.random.permutation(np.arange(len_train))
subset = Subset(train_dataset, indices[:int(len_train/self.M*(j+1))])
dataloader[phase] = torch.utils.data.DataLoader(
subset, batch_size=self.batch_size, shuffle=phase=="train", num_workers=4)
data_size[phase] = len(subset.indices)信頼度ベースで追加する場合(実装全体:https://github.com/HironoOkamoto/active-learning/blob/main/active_learning.py)
for j in range(self.M):
phase = "train"
len_train = len(train_dataset)
if j==0:
indices = np.random.permutation(np.arange(len_train))
N = int(len_train/self.M)
init_indices = indices[:N]
rest_indices = indices[N:]
subset = Subset(train_dataset, init_indices)
rest_subset = Subset(train_dataset, rest_indices)
else:
init_indices = np.append(init_indices, new_indices)
rest_indices = np.delete(rest_indices, argsort[:N])
subset = Subset(train_dataset, init_indices)
rest_subset = Subset(train_dataset, rest_indices)訓練データの残りの部分を利用して信頼度計算
if epoch_ == self.epochs - 1:
print("select data")
model.eval()
conf = []
for xs, _ in tqdm(restloader):
xs = xs.to(device)
with torch.no_grad():
outputs = model(xs)
softmax_max, preds = torch.max(torch.softmax(outputs.data, 1), 1)
conf.extend(softmax_max.detach().cpu().numpy())
conf = np.array(conf)
argsort = conf.argsort()
new_indices = rest_indices[argsort][:N] # 信頼度が低い部分を取り出すCIFAR10の分類の実装:https://github.com/HironoOkamoto/active-learning/blob/main/main.py
おまけ
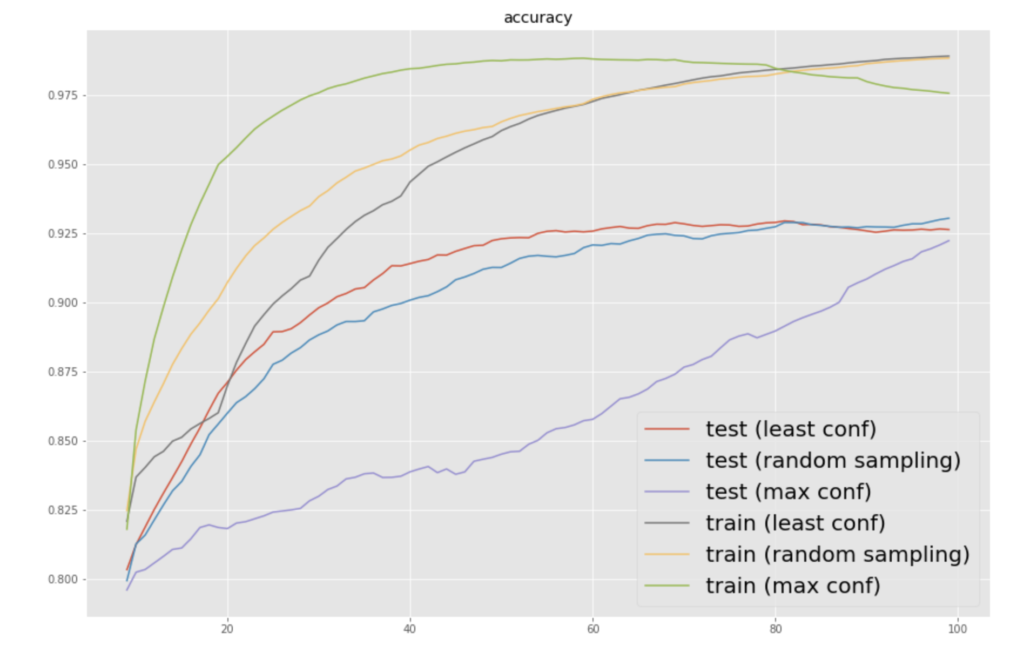
信頼度が高い順にデータを追加していく(max conf)と、非常に収束が遅くなるという当たり前の結果を確認した
信頼度の高いものを訓練データに入れて学習し、その予測がすべて正しい場合、つまり半教師あり学習のself-trainingの上限の結果とみなすこともできる


コメント