書誌情報
論文タイトル:Fully Unsupervised Diversity Denoising with Convolutional Variational Autoencoders
この論文を一言でいうと:ノイズ画像のみを訓練画像とし、VAEの枠組みを利用してノイズモデルを学習させることで、確率的に複数のクリーンな画像を提示することを可能にした
その他参考論文:Fully Unsupervised Probabilistic Noise2Void
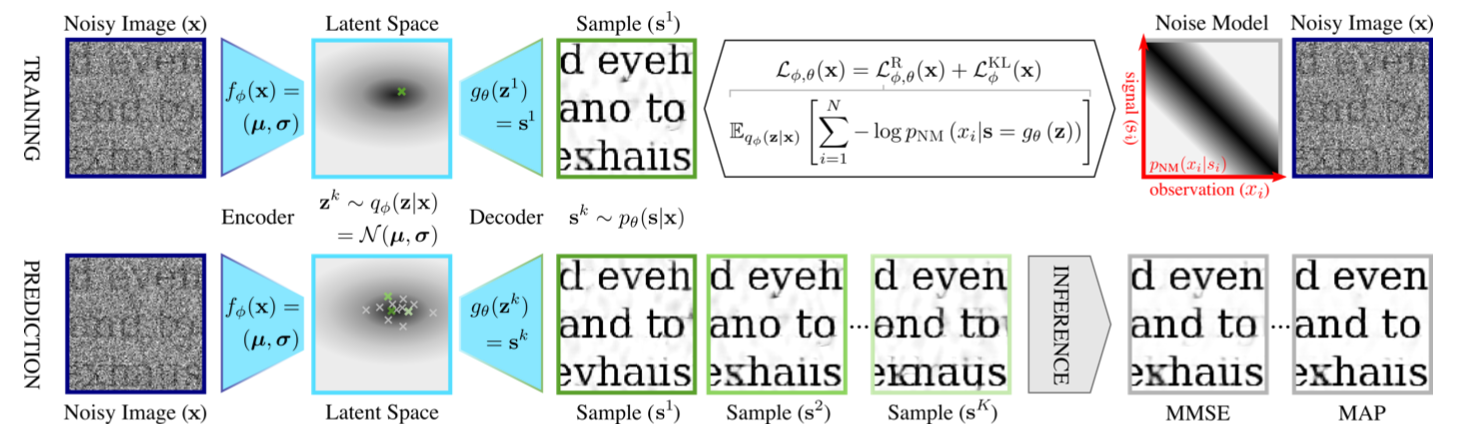
実験結果


ノイズ画像から、ありえそうなデノイズ画像を複数出力できるのは面白い
上図より、複数のサンプルされた画像の単純な平均(MMSE)よりも、ある一つのサンプルのほうが真の画像に近いことがあるということがわかる
モザイク画像から複数の候補とかをだせるようにしたら面白そう
提案手法
生成過程
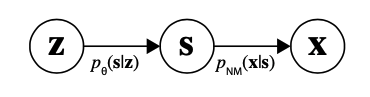
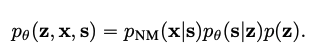
$x$はノイズ画像、$s$はクリーンな画像、$z$は$s$を生み出す潜在変数
$p(z)$は標準正規分布、$p_\theta(s|z)$はここではデルタ関数($\delta(s-g_\theta(z))$)とする
さらに推論モデル(エンコーダ)として$q_\phi(z|x)$も用意する
$p_{NM}(x|s)(=\prod_i^Np_{NM}(x_i|s_i))$はノイズモデルであり、ピクセルごとに独立であることを仮定している
ノイズモデルは[Prakash+ 2020]を参考に混合ガウス分布としているとのこと
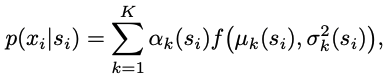
訓練

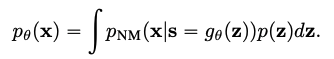
$p_\theta(x)$の対数尤度最大化によってモデルを訓練したいが、上式はintractableなので、VAEと同様にELBO最大化することでモデルを訓練する
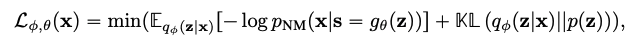
推論

最終的な目的はノイズ画像$x$からクリーンな画像$s$を推論すること
そのために、$x$から$z$をエンコーダ$q_\phi(z|x)$で確率的にサンプリングし、決定的関数$s=g_\theta(z)$で$s$を求める
サンプルの平均的な画像(MMSE)をもとめるか、MAP推定する(mean shiftアルゴリズムを使う)ことでいい感じのクリーンな画像が得られる
付録:昔発表したデノイジング系論文の資料
Noise2Voidからの発展
- High-Quality Self-Supervised Deep Image Denoising
- スライドシェア:https://www.slideshare.net/DeepLearningJP2016/dlhighquality-selfsupervised-deep-image-denoising
未知のノイズ分布に対応する研究
- Variational Denoising Network
- スライドシェア:https://www.slideshare.net/ssuser9eb780/variational-denoising-network


コメント