書誌情報
論文タイトル:SSD: A Unified Framework for Self-Supervised Outlier Detection
ICLR2021 accepted
この論文を一言でいうと:自己教師あり学習の手法の一つである対照学習で特徴空間の学習を行い、k-meansを用いて分布内データのクラスタを推定し、特徴空間におけるマハラノビス距離を計算することで、分布内データのクラスラベルを使わずに分布外検知を行う
この論文での分布外検知の問題設定
よくある分布外検知の問題設定では、分布内データのクラスラベルが使えることが多い
例えば、犬・猫・鳥を分布内データとして、それ以外を分布外データとする。このとき、犬・猫・鳥というクラス情報を使ってよいということである
一方、この論文では分布内データのクラスラベルを使わずに、それが分布内データであるという情報だけで、分布外データを検知する問題設定となっており、実はこれはけっこう難しい
よくある例として、VAEで分布内データ(CIFAR10)を使って対数尤度の最大化するように学習しても、分布外データ(SVHN)の対数尤度が分布内データよりも逆に大きくなってしまう現象が確認されている[Nalisnick+ 2019]
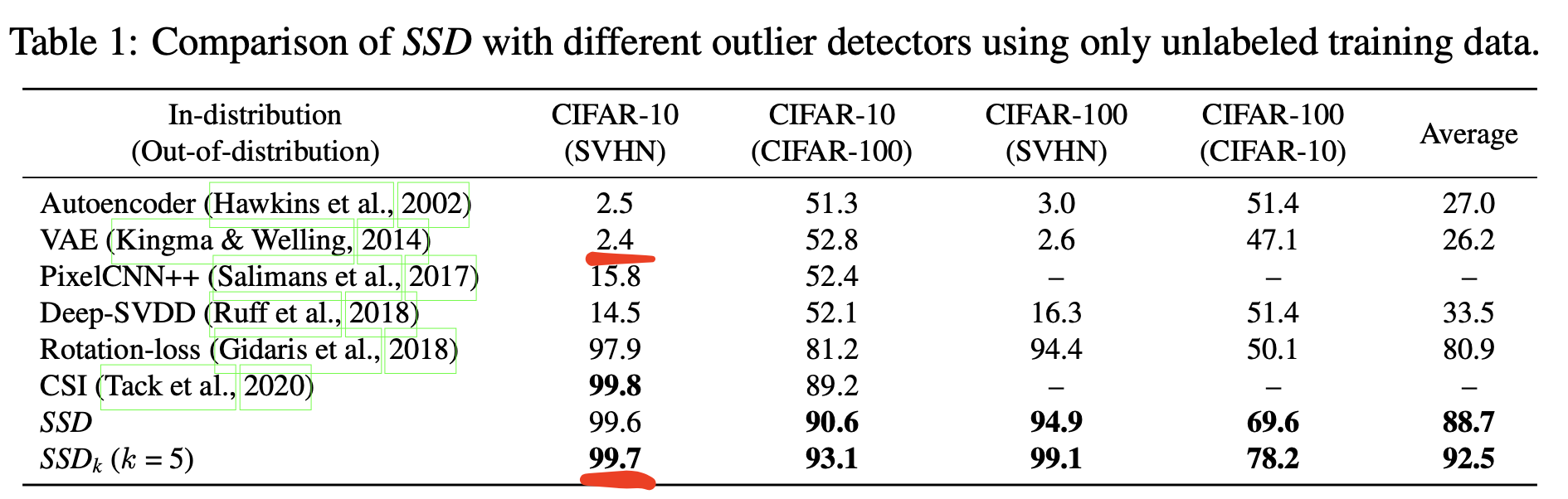
再現実験でも上記と同様の結果がでている一方で、この論文の手法はまともな結果がでているので興味深い
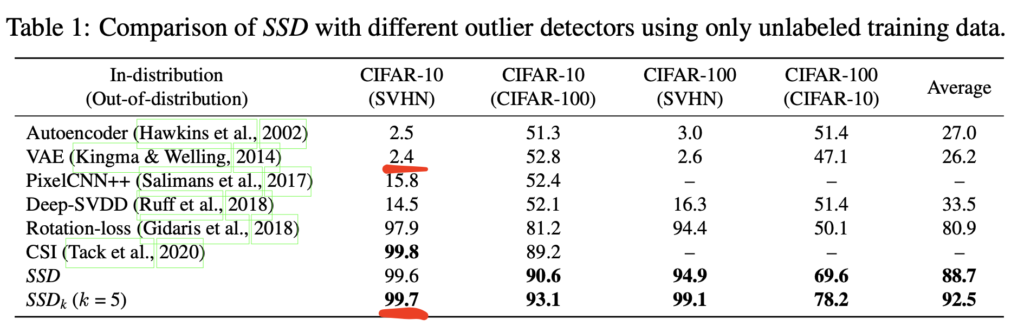
注1:CSIもけっこう精度でているが、同じように対照学習を利用した手法だから、まあそうかなという感じ。SSDの方が手法としてはスッキリしていてヒューリスティクスが少ないイメージ。CSIの解説は昔ここに書いた
提案手法
本論文の手法はおおまかには次のステップである
- 対照推定によって分布内データの特徴表現を学習する
- 特徴空間上でk-meansを利用してクラスタリングを行う
- 上記クラスタの中で最も距離が近いサンプルのマハラノビス距離を分布外スコアとする
対照推定によって分布内データの特徴表現を学習する
SimCLR[Chen+ 2020]で述べられているNormalized temperature-scaled cross-entropy (NT-Xent)による対照学習を利用している(対照学習についてはここにまとめている)
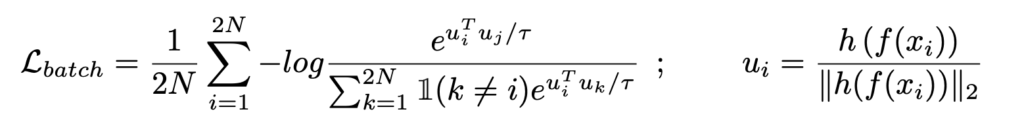
特徴空間上でk-meansを利用してクラスタリングを行う
といいつつ、実験でk=1が良かったから、結局教師なしクラスタリングしてないみたいだが…? 唯一の新規性が…
上記クラスタの中で最も距離が近いサンプルのマハラノビス距離を分布外スコアとする
よくある方法。特徴空間の分布をガウス分布と仮定して、中心から離れていれば分布外データとみなす
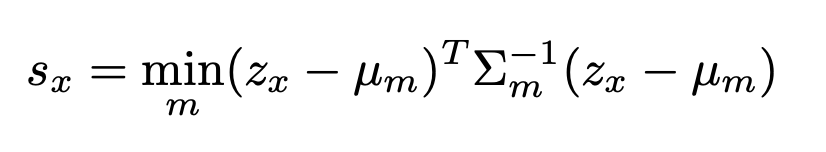
その他提案手法
分布内データのラベルを使わない問題設定に着目しているといいつつ、ラベルを使う場合の問題設定における手法の提案も行っている
対照学習は、クラス情報を用いていないため、クラスが同じであっても異なるサンプルは特徴空間上で離れるように学習する
対照学習の中でも、教師あり対照学習[Khosla+ 2020]というものがあり、こちらの方法はクラスラベルが同じであれば異なるサンプルでも特徴空間で近づくように学習する(ロス関数は下式)
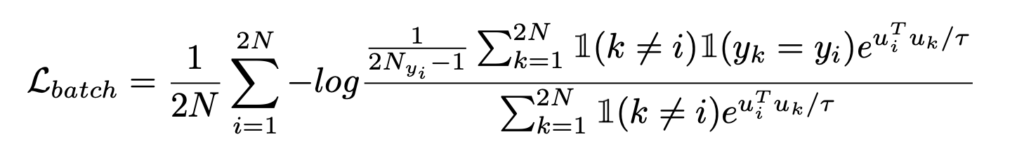
よって、ラベルが使える場合はSimCLR[Chen+ 2020]ではなく教師あり対照学習[Khosla+ 2020]を使って、特徴空間を学習し、その空間上でマハラノビス距離をもとに分布外スコアをもとめるという方法を提案している
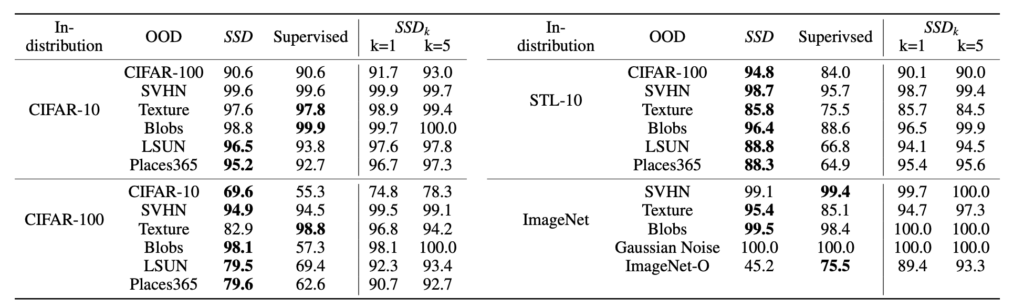
精度もそこそこでているが、必ずしもSSDよりもSupervisedの方がいいとは限らないらしい
ちなみに、SSD_kはfew-shot OOD detectionという問題設定を考えているもので、ターゲットOODのデータを少し使ったら精度あがるよ、というもの
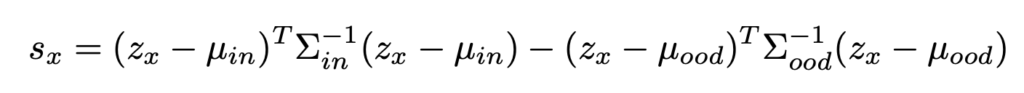
分布外スコアは上記のものをつかう
感想
いろいろと最近の手法をまとめてくれているのでわかりやすかったが、提案手法に新規性は特に感じられなかった
対照学習はやはり分布外検知にも有効であるということがわかった

コメント